Why do we need a blockchain? This is a common question, one that has been asked a great deal over the last decade. However, once we delve further into the economics, it is clear that there is more to this technology than just hype. In this note, we share the lessons learnt from years of designing, testing and producing both Distributed Ledger Technology (DLT) systems and traditional databases. We explain the differences of both technologies from a business and project management perspective, as well as their ultimate value propositions.
Problems with Traditional Databases
All software interacts with data and is at the heart of IT systems. Over time, the organisation of data has become a field of its own: it is useful to store data in a central repository on which multiple users can work simultaneously, sometimes even with different applications. However, many companies still rely on old mainframes, coding languages and data architectures. These mainframes are often messy with few individuals within large organisations able to understand and use their bespoke and usually poorly designed architecture. This makes them difficult to maintain, upgrade and replace. As an example, in April 2020 during the COVID-19 pandemic, the New Jersey governor made a public appeal for COBOL programmers to fix their public unemployment IT system, which could not scale with the sudden influx of unemployment claims.1,2
The way these systems store and provide access to data has greatly evolved, often in line with new programming languages which allow for the best utilisation of the new data architectures. Unfortunately, these new data architectures were often refactored in older programming languages, as it is easier to upgrade just the data model than to also completely upgrade the software. This shortcut means not all of the benefits of the new data architectures can be fully realised. For the full benefit of a new data model, a full upgrade of both the data model and the software’s codebase is required in tandem.
There are several different parts to data architecture, beyond just the database itself, which need to work together to provide a usable company database. It is the poor or bespoke design of the non-database components, and how these components interact, which cause most data infrastructure issues.
Data Infrastructure
Digital infrastructure consists of many layers (or a “stack”) of individual pieces of software which build on top of another, known as a software, or infrastructure stack. Each layer of software is independent of each other (e.g. you can freely use many different Windows applications on a Windows operating system). Each new layer of software uses the functionality offered by lower layers of this software stack, while adding new functionality for higher software layers, and ultimately the end users. For example, Microsoft Word enables users to use text documents, while relying on the operating system to get input from the mouse and keyboard. Figure 1 below provides a sampled diagram of how everyday computer applications or digital services are dependent on the operating systems and hardware which are below them in the software stack. Data Infrastructure is used by the top services and network layers of this simplified software stack.
Figure 1: Where Data Infrastructure fit into the Software Stack
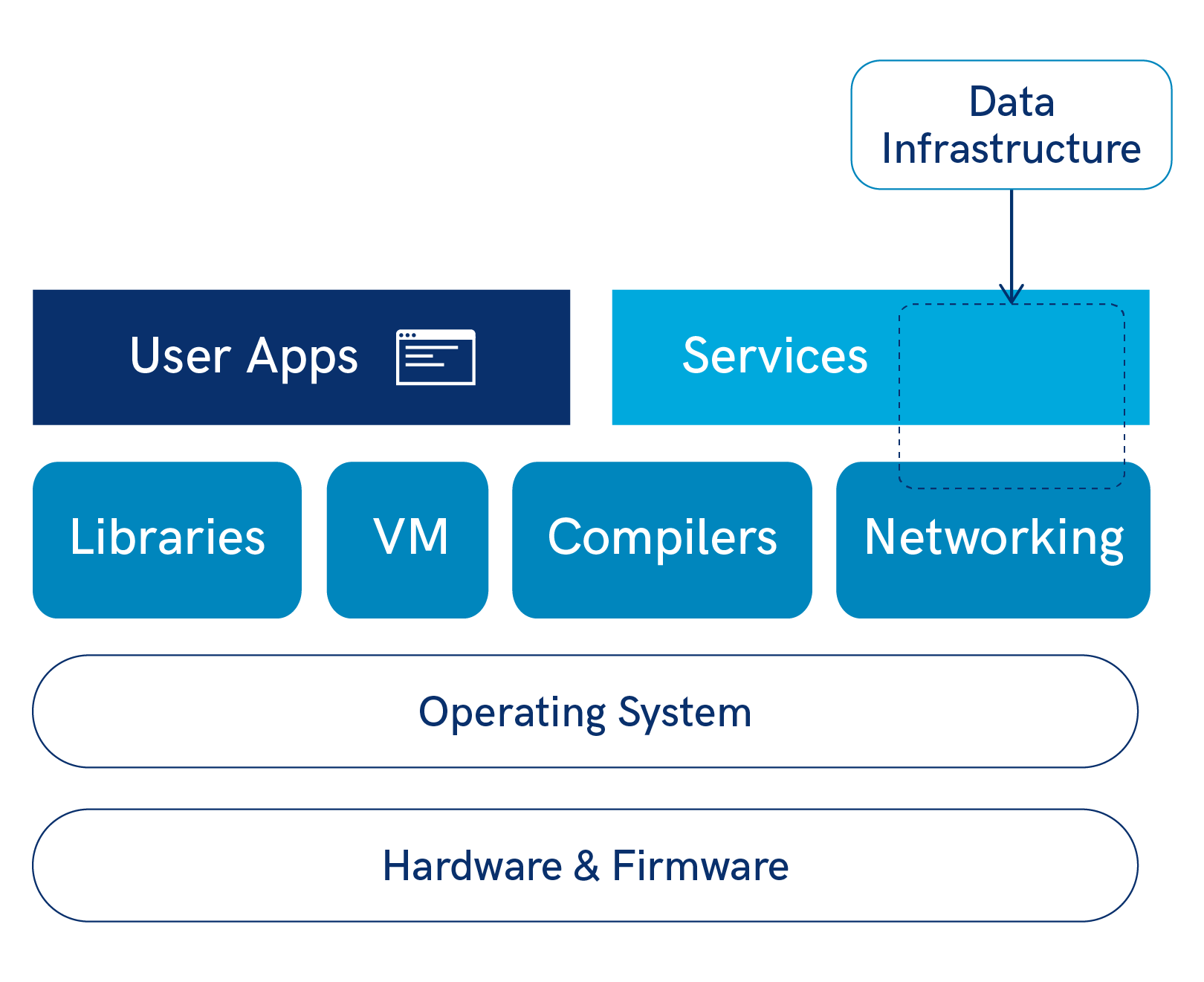
Data infrastructure itself provides three separate functions, which are provided by three separate layers of software:
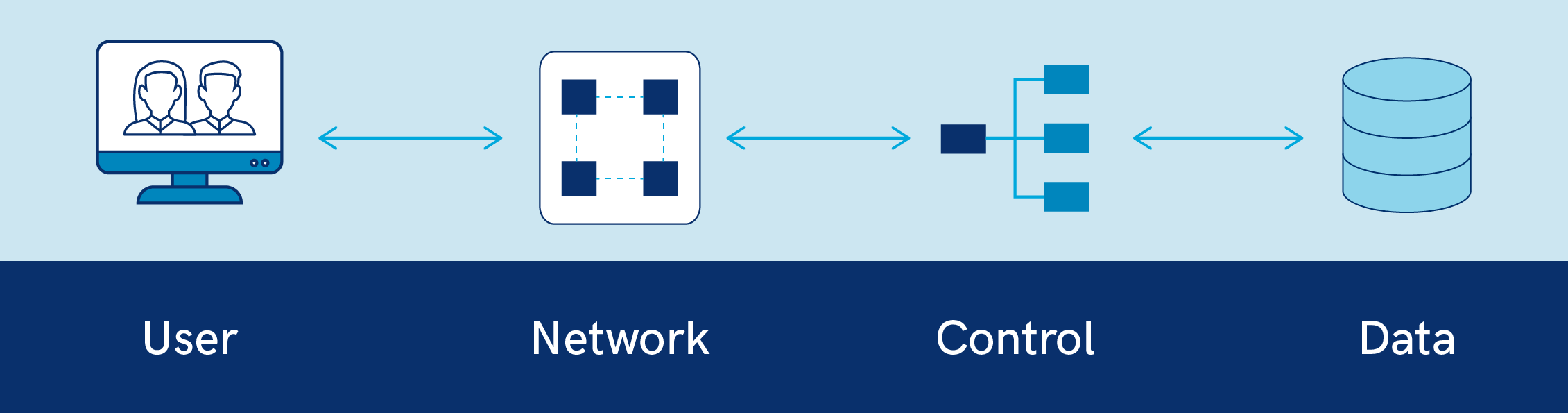
- Data layer: this layer represents data and stores it.
- Control layer: this layer gives access to the data, running queries and controlling and enforcing access rights.
- Network layer: this layer gives network participants access to the control layer.
Figure 2 below illustrates how these layers interact with each other.
Figure 2: Different Layers of Data Infrastructure
Design of DLTs
Distributed Ledger Technology is a novel data architecture. It forces developers to adopt a clearer and more standardised representation of data, the logic around data, access controls, data storage and validation as well as other layers of the software stack. However, as with other standardised hardware and software, it is more complicated than what is currently used in many instances. This currently makes projects harder and more expensive to change. For small use cases where trust or robustness is not a major concern (i.e. one is not building a large software stack on top), traditional databases are far easier, quicker and cheaper to use. This is also in line with the fact that more experienced developers who can understand DLT from a business perspective are often in limited supply and more expensive due to greater demand.
This is much the same as companies and governance structures. The transparent reporting and strict governance structures required by publicly-listed companies are best practice and ensure that they run in the best interests of shareholders. However, these governance structures are extremely cumbersome and expensive, and thus are not implemented in privately held companies where trust is not such a large issue.
The wider economic benefits of DLT adoption in enterprise IT systems include: vendor independence; software quality improvements; reduced need for highly customised and inflexible systems; and, new opportunities for business process automation and digital transformation.3 By adopting open standards for both data models (blockchain transactions) and data processing (smart contracts), DLT enables vendor independence and lower total cost of ownership (maintenance and upgrades) over the long term.
Why is Standardisation Important?
Enterprise Resource Planning (ERP) solutions have created enormous value for business across many industries.4 Whilst there is some standardisation in their design, there is still a large amount of customisation available - from integrating with existing IT systems, specific database requirements and software bug quick fixes. Allowing global companies to customise their designs makes them more prone to being locked up in systems that are very expensive to upgrade. Large ERP project failures include: US AirForce, Lidl, MillerCoors, Revlon and Vodafone.5 Major banks also routinely require multiple attempts before they can successfully overhaul their core digital infrastructure, with each individual attempt taking up to several years and costing upwards of $100 million.6
Standardisation is an ongoing, multi-decade process, which can generate large economies of scale and scope. It is easy to miss as it happens gradually, and once it succeeds the pre-standard era disappears and is quickly forgotten.
Between the 1960s and 1980s, the semiconductor industry experimented with various hardware architectures and instruction sets. For a long time, we have now only employed two major architectures. The CISC x86 architecture promoted by Intel and supported by AMD is used by virtually all server data centers on which cloud computing is run.7 The ARM RISC architecture on the other hand is used by virtually all smartphones.8 Standardising architectures greatly reduced software development costs and toolchain quality. It also allowed the industry to grow faster and to focus research budgets on other important problems.
Operating systems have also become standardised. From a multitude of independent UNIX vendors, we now have standard operating systems: MacOS and Windows 10 on personal computers; Linux on servers; and Android and iOS on smartphones. This is driven by the economics of network effects. Remember Blackberry and Microsoft phones? Nokia Symbian OS? These operating systems may have been technically brilliant, but it was not economical for companies to build apps on so many different platforms. Standardisation enabled significant higher market growth as less specialised developers could build more apps and reuse more code libraries. This reduced development costs for software providers.
Besides hardware and operating systems, the networking layer has also largely benefitted from standardisation. Nowadays the Internet is taken for granted, available on a multitude of devices and platforms. This wasn’t always the case. Compuserve, AOL and Minitel, company-wide retail intranets competed with the Internet in the 1990s. By defining protocols to connect every network independently of the infrastructure operator and the application service providers, the Internet Protocol suite revolutionised IT. First with email replacing letters and fax, then access to information with search engines, and later retail distribution channels for a multitude of industries, and so on.
Standardisation of Data Architectures
DLT enables a similar transformation of the Data Infrastructure software layers. By standardising information representation and transformation at the data infrastructure layers, better solutions emerge with similar cost savings. DLT not only reduces the need for customisation, but also removes the option for quick fixes and poor software design choices which end up costing clients more in the long run. While this increases the difficulty of implementing bespoke DLT systems relative to simpler databases, standardised DLT platforms increase the ease of system interoperability and system upgrades. IT budgets can then be re-focused on the digital transformation of large distributed business processes, which are currently highly inefficient and overlooked.
How does this work, and why do it? We use computers and software to store and transform data. In the first era of custom software development, each software read and wrote data in custom proprietary formats. It was hard or impossible for other companies to write software that could process someone else’s data formats. The typical example is COBOL and hierarchical flat files. IBM was the market leader on this. From an end user’s perspective, Microsoft Word in the 1990s is also a good example of this.
The entity/relation model and the SQL language to implement it enabled a new wave of innovation in the 80s/90s. Migrating from mainframes to PC servers and a standardized data model opened competition. Oracle Corporation was created in 1977 to capture the value of these new markets. In 2019, this company was the second-largest software company by sales.9
Later, data started being written into less structured text formats instead of binary and SQL, such as HTML, XML, and now JSON. The logic processing the data is hidden in the cloud on servers (Facebook, Gmail, Linkedin, or SAP, Salesforce, Oracle ERP, etc.). Not all data is actually accessible in these formats, but the data that is “exposed” does use these formats at the network level. This data moves from a company cloud to the consumer web browser or app, with data saved on a mobile phone or laptop. Large SQL proprietary databases exist and are not directly accessible or even exportable. This interactive web content is commonly referred to as Web 2.0.10
Compared to the first and second eras, the third era enabled amazing innovations, new business models, free interconnected services using Web API. This made it easier for users to download some of their data, and in some cases all of it.
Table 1: Evolution of Data Infrastructure
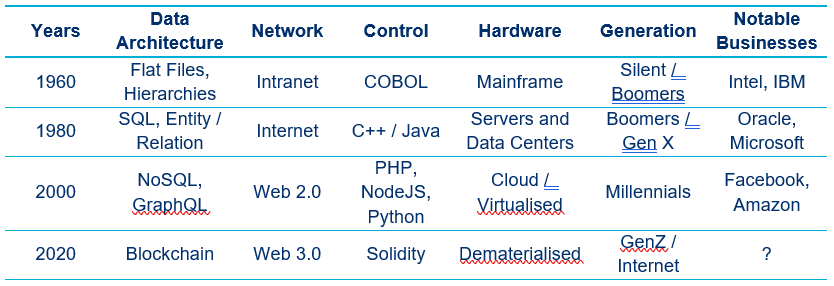
The largest companies extract value by processing enormous amounts of data in the cloud, tuning algorithms with datasets that their competitors cannot reproduce. This creates an AI imbalance, as a company with billions of pictures with metadata (people’s names) can teach an AI to be much more accurate at facial recognition for instance. While data exchanges follow easy to process data formats, they are “copies” of the reference master datasets which are hidden on large private databases. This is sometimes called the “deep web”.
DLTs, such as blockchain, now mark the start of a fourth era. Some of the data and logic are exposed outside companies. Instead of only exporting JSON data, we store and share the reference / master data (the one that was in a private database in the Web 2.0 era) on a public blockchain. As well as data, we also store some control logic, so-called smart contracts, on the blockchain. Data models / storage, control interface and network protocols are combined and standardised together. Anyone can verify the computations applied, and that the input data applied to this logic code generates the same output data. This way of storing and processing data is naturally more expensive than in the previous approach as some operations are repeated. However, it creates greater benefits by increasing trust, facilitating re-use of data and logic, and can enable significantly greater network effects. These enable greater economies of scale and scope than traditional databases.
Conclusion
As with mass production, it is the standardisation of many parts of the software and hardware stack which has brought affordable technology to the masses. However, there are still layers of the software stack where significant costs could be saved though increased standardisation and interoperability, notably the data infrastructure layers. Misaligned economic incentives, trust issues and technology limitations have been a key reason for the slow standardisation of this software.
DLT is a unique software architecture which is slow and inefficient by nature, but solves the economic and trust issues which centralised software architectures, by their fundamental design, are limited by. It improves transparency and resiliency. As with everything there is a trade-off. Where trust is not an issue, traditional databases will prevail, but where trust or information asymmetry market failures exist, DLT can sustainably improve market outcomes as this technology develops and becomes more standardised.
Culture changes will be required and businesses will need to update their way of working to deliver the true value that DLT promises. It takes time to change old habits. But in the end, the free market will prevail, as it always does.
Footnotes
1 This was typical of COBOL programming language running on mainframe computers in the 60s and is still at the heart of many company mainframes.
2 For more information on the appeal for COBOL programmers by the Governor of New Jersey, see: https://nymag.com/intelligencer/2020/04/what-is-cobol-what-does-it-have-to-do-with-the-coronavirus.html.
3 These new digitalisation and automation opportunities stem from the economic and trust limitations of traditional database infrastructure which DLT can solve. For more information, see DLT and the Hold-up Problem.
4 Enterprise Resource Planning is business management software - typically a suite of integrated applications - that an organisation can use to manage data. For more information, see: https://en.wikipedia.org/wiki/Enterprise_resource_planning.
5 For more information on failed ERP projects, see: https://www.theregister.co.uk/2019/12/12/erp_disaster_zone_the_mostly_costly_failures_of_the_past_decade/
6 For more information about the large cost of banking digitalisation, see: https://11fs.com/blog/billions-spent.
7 For more information on the dominance of Intel and AMD in non-mobile CPUs, see: https://www.sdxcentral.com/articles/news/data-center-revenue-drives-intel-to-record-q4/2020/01/ and https://finance.yahoo.com/news/intel-vs-amd-reviewing-rivalry-160718187.html.
8 For more information on the dominance of ARM in mobile CPUs, see: https://www.arm.com/-/media/global/company/investors/PDFs/Arm_SBG_Q1_2019_Roadshow_Slides_FINAL.pdf?revision=9e3e50c9-9b76-48f1-b02c-a30f5b4f2ee4, slide 12.
9 For a list of the largest software companies, see: https://www.forbes.com/global2000/list/#industry:Software%20%26%20Programming.
10 The static web pages of the 1990s, where users simply downloaded information in a one-way directional channel from a website (without any real interactivity enabling a dual information flow from the user to the website) is known as Web 1.0.